
Untangling homonym representations in BERT, Part 2: Phenomenology
In this post, I’ll use the tools from the previous post to examine BERT-Base, an open source deep transformer model which performs well on natural language processing benchmarks (see the first link). We will find that in deeper layers, this model has learned to represent homonyms in such a way that they can be easily discriminated. This post will cover just the phenomenology: to what extent are the representations of two homonyms disentangled from each other in each layer? In the next post, we will dive into how the representations come to be disentangled from each other.
To approach these questions, I made use of a dataset of homonyms used in a corpus of movie and TV subtitles, helpfully compiled by the authors of Rice et al. 2018. This dataset consists of many sets of homonyms, which might be interpreted in one of several senses based on context. For example, the word “pack” commonly refers either to a verb (“to pack one’s bags”) or to a noun (“a pack of wild dogs”). I manually categorized the uses of “pack” first according to their part of speech. Then, I examined how the representation of each use of “pack” related to the semantic distinction between the noun and verb form, in each layer of BERT.
First, we consider the input space. The inputs to BERT are a series of individual tokens, corresponding to first approximation to individual words. The first example line in the dataset consists of this series of tokens (separated here by spaces): ‘Come on , pack it up !’. As a first step, each token is converted independently via lookup table to a unique high (768)-dimensional vector, known as a “word embedding.” This embedding is learned, and these types of learned embeddings (for example, like word2vec) have been found to encode a large amount of semantic information about the word. However, this is all useless to us, as to start, the word embedding for “pack” will remain the same regardless of whether it is being used as a noun or a verb. However, in the next step, this high-dimensional word embedding is added to a high-dimensional learned positional embedding, which encodes the location of the word in the sentence (e.g. here, “pack” is the fourth token). A first reasonable question to ask, is whether this positional information is sufficient to separate nouns from verbs. For example, “pack” as a verb can appear at the beginning of a sentence (e.g. as a command), but “pack” as a noun will probably do so only rarely.
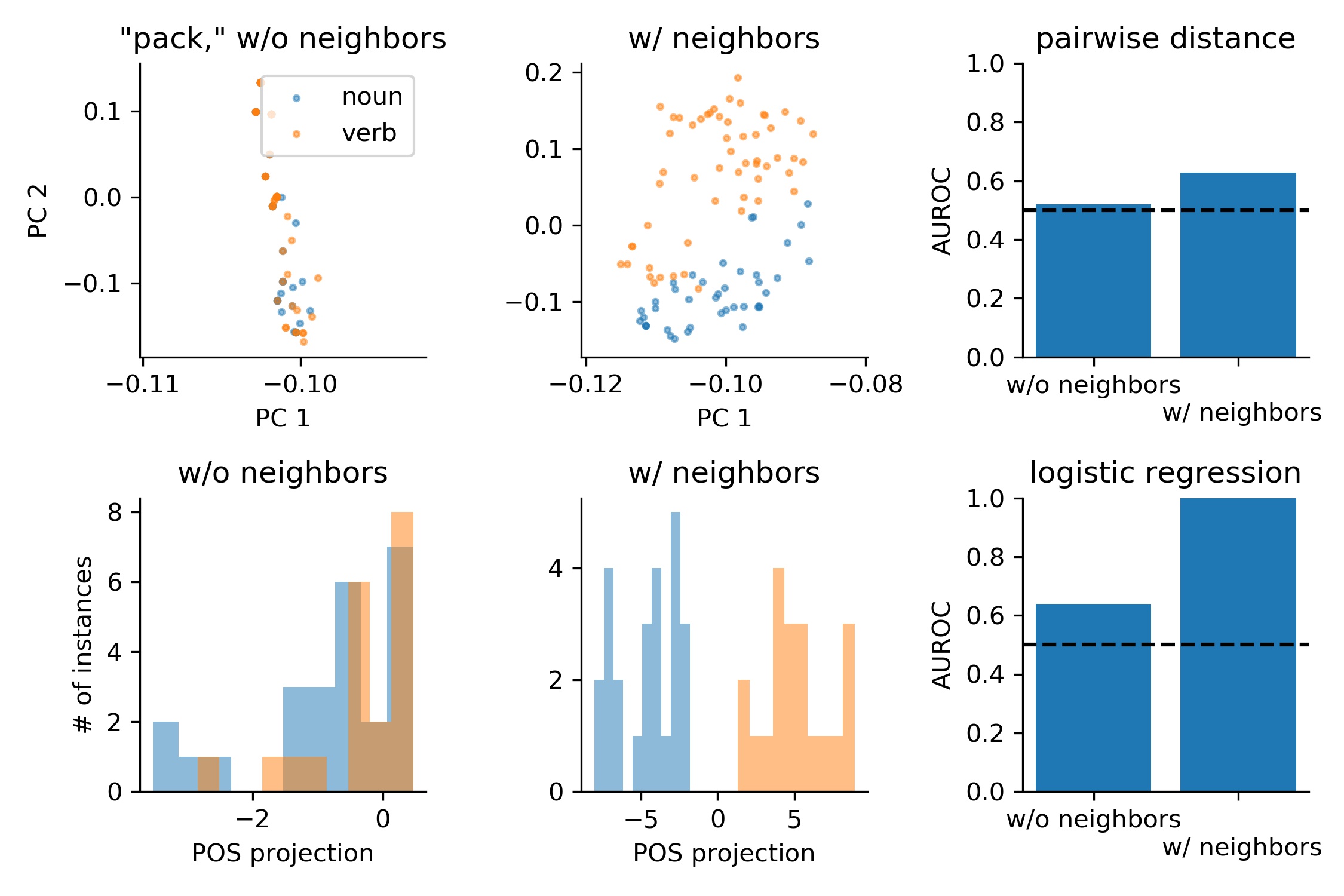
Our first tool will be simply to visualize the distribution of representations of each homonym in the input space. As a first pass, we simply perform principal component analysis (PCA) on the high dimensional space of input embeddings corresponding to the word “pack,” and plot the first two principal components (A). Because the first two PCs contain the most variation of any two axes, we expect these to be representative of whether the two homonyms are represented similarly or dissimilarly. As we can see, the two distributions are highly overlapping.
Transformer models are able to progressively adapt independent, non-contextual representations into contextual representations by mixing information from the surrounding words. We next asked whether, together with the two neighboring word representations, there was sufficient information in the inputs to easily discriminate the two homonyms. Performing PCA, as before, but this time on the concatenated vector of the three adjacent word representations for each instance of the homonym, we again plot the first two PCs (B). Here already, the distributions are largely non-overlapping, but not highly separated. For representations near the boundary between the two point clouds of representations, its nearest neighbor representation might well have a different part of speech.
To quantify these tendencies, we use the tools developed in the previous post. In the language of the previous post, we first examine discriminability in the few-shot learning regime. Therefore, we first compute the AUROC between within-homonym and between-homonym pairwise distances in the input space, either excluding or including nearest neighbor representations (C). As expected from the PCA scatter plots, we find that the AUROC is close to 0.5 without taking neighboring representations into account, meaning these distributions are difficult to discriminate. On the other hand, including the neighboring representations increases the AUROC above 0.6. In the few-shot learning regime, we would suppose from this that the input representations of the two homonyms cannot at all be linearly discriminated without context, but begin to be (somewhat poorly) linearly discriminated with the neighboring word representations as context.
Next, we examine the many-shot learning regime. Given half of the entire dataset, can we train a linear model that can discriminate between representations of the two homonyms (in the other half of the dataset)? We plot histograms of the two representations, projected on the learned “part of speech” axis, for models trained on the inputs without context (D) and with context (E). In fact, for the context-free inputs, the distributions turn out to be not at all separable (AUROC = 0.5), whereas for the inputs with surrounding context, the distributions turn out to be perfectly separable (AUROC = 1) (F).
Therefore, if the layers of BERT are performing operations that are useful for progressively separating the representations of these two “pack” homonyms, we can conclude that (1) it may be by mixing information from neighboring word representations, and (2) it is likely that improvements will be made in the few-shot linear discriminability, rather than many-shot, as the many-shot linear discriminability of the inputs together with neighbors is already perfect.
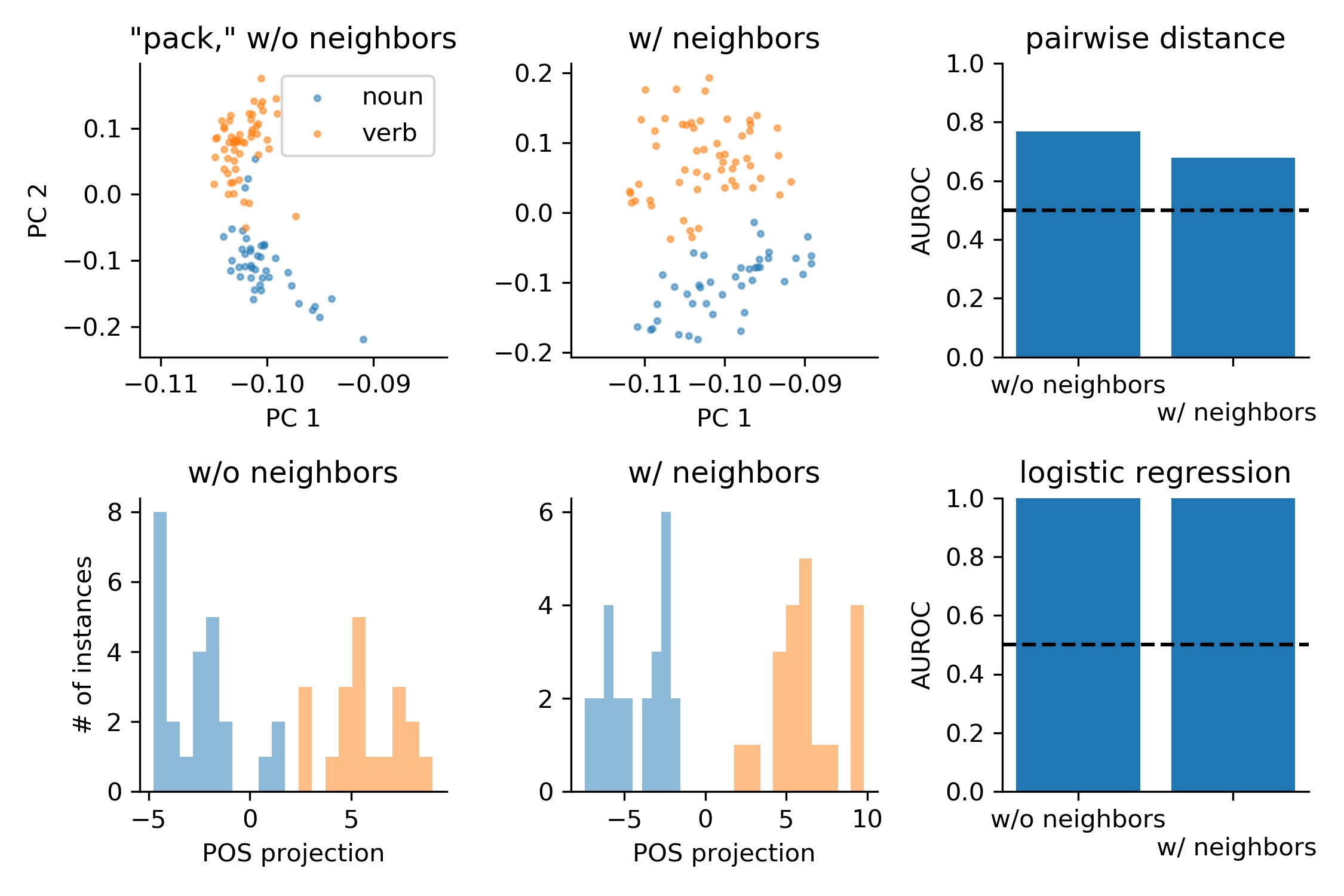
We next examine how these measurements change, starting at the outputs of the first layer of processing in BERT. We perform the same measurements as before, and find that in the few-shot learning regime, discrimination performance based on the word representation alone is at least as good as if we included neighboring word representations (A-C). In the many-shot learning regime, performance is more or less perfect, with or without neighboring word representations.
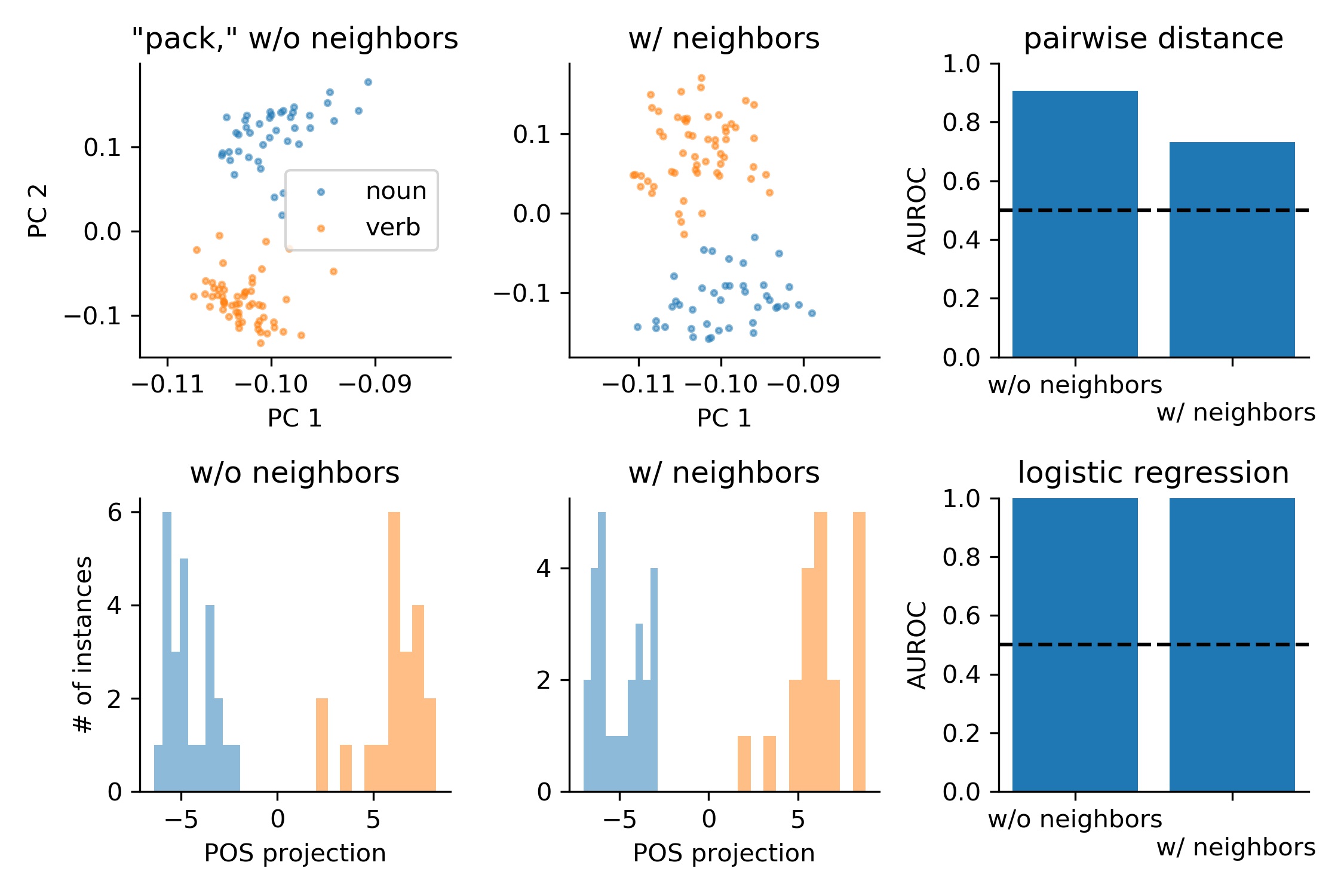
The few-shot learnability of representations after the second layer of processing is better still.
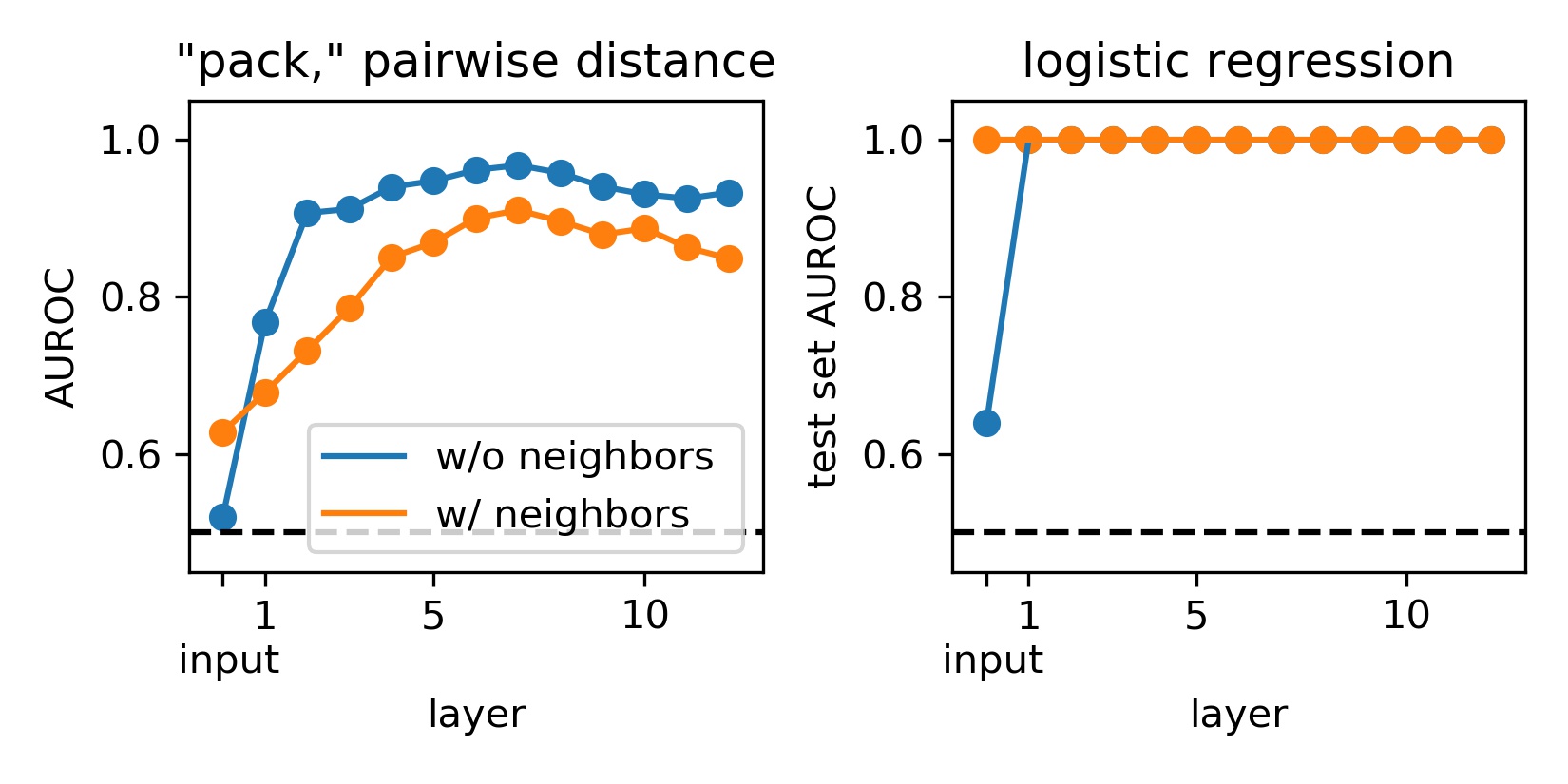
In keeping with the trends we observed for the first two layers of processing, we find that this increased few-shot discriminability remains stable into the later layers of processing (A). Further, the more or less perfect many-shot discriminability likewise remains stable (B).
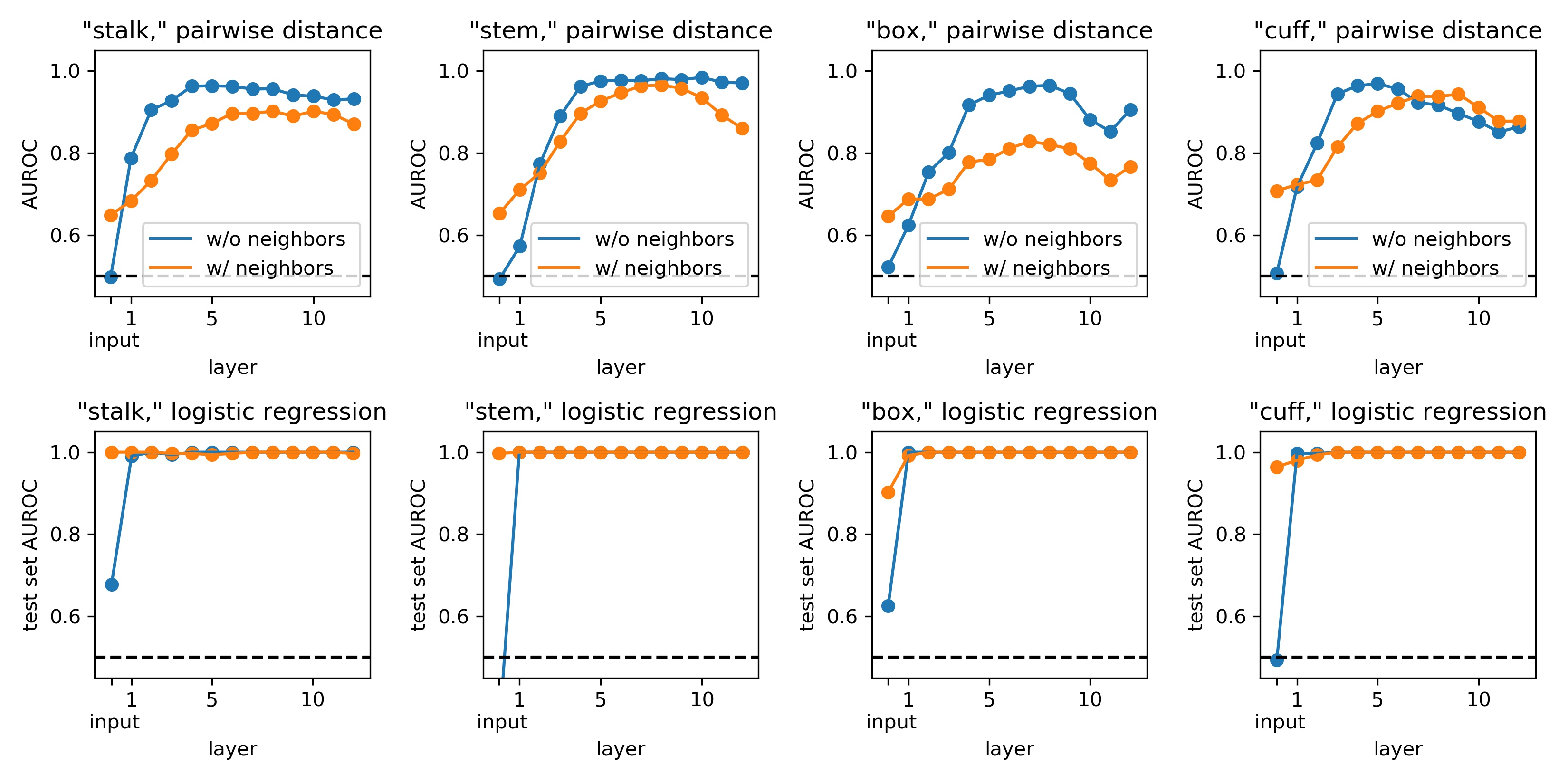
If we repeat the same analysis on a few more pairs of homonyms that can appear either as a noun or as a verb– “stalk,” “stem,” “box,” and “cuff”– we find that similar patterns hold (A-D): few-shot discriminability is nearly chance for the input, and somewhat above chance for the input representations concatenated with neighboring word representations. Discriminability for the input representations alone, without neighboring word representations, increases gradually across the first few layers of processing, saturating at a level somewhat above the discriminability of the concatenated inputs with neighbors. From this, we conclude that in general, word representations starting in intermediate layers of BERT take into account information from the surrounding word context that is specifically helpful for disambiguating the meaning of the word in question (as evidenced by the increasing discriminability of part of speech information), and ignoring distracting variability present in the neighboring word input representations (as evidenced by greater discriminability in the word representation, than in the concatenated input representation of the word and its neighbors).
Many-shot learnable linear discriminability is more or less perfect in every representation except the input representation (E-H).
In fact, then, BERT seems to learn intermediate layer word representations that prioritize discriminability of homonyms according to what we might think of as a semantically important feature, part of speech information. This presumably comes at the expense of discriminability of representations between instances of a word that we might think of as semantically similar.
In the next posts, I will dive deeper into the network mechanisms that seem to support this representation, as well as the encoding of finer-grained sense information (think “these problems stem from childhood trauma” vs. “stem the flow of goods”).